Applying Linear Regression to Illustrate Basic ML Concepts
Linear Regression isn't just a model; it's a gateway to understanding fundamental terms and concepts that are used to accomplish most forms of machine learning. This section first defines this predominant machine learning paradigm, and then demystifies it using analogies to linear regression.
2.5 The Machine Learning Paradigm
Fundamentally, in almost all forms of machine learning, code is written that tweaks the parameters of a model in a process governed by the chosen hyperparameters with the goal of optimizing a cost function.
- Model
The structure, formula, or framework that is designed to learn from data, or represents what has been learned.
"What is it that is learning?"
- Parameters
The components of the model that are adjusted during learning/training, usually weights or coefficients in the model structure or formula
"What is being tuned during learning?"
- Hyperparameters
Values that govern model structure, training or behavior but are predetermined and do not change
"How should tuning occur?"
- Cost Function
A formula that defines the goal of parameter tuning; calculates and grades the appropriateness of a model and its current set of parameters
"What is the goal of tuning?"
Overwhelming? Don't worry, in reality you have already interacted with each of these concepts in linear regression! Let's now understand how this paradigm presented itself in the linear regression example.
2.6 Understanding Parameters in the Context of Linear Regression
In linear regression, parameters are the values that are iteratively adjusted to tweak the line to better fit the data: the slope and intercept!
Parameters in Linear Regression:
Slope (m): Determines how steep the line is.
Intercept (c): Defines where the line intercepts the y-axis.
These parameters are what the model learns through procedured trial and error during the training process. They are crucial as they define the model's predictive capability.
2.7 The "Model" in a Linear Regression Model
Given parameters that have been tweaked and tuned, the model can transform inputs to predict outputs. Therefore, it is the representation of what has been learned. In linear regression the model is simply the formula of the best-fit line with input parameters (slope and intercept)
After tuning the slope and intercept parameters, the resulting linear equation is what we refer to as our trained model.
2.8 Hyperparameters: Tweaking the Learning Process
Hyperparameters are the settings or configurations that govern the overall process of learning or structure of the model.
Hyperparameters in Linear Regression:
Iterations: The number of passes through the dataset. In this case, each pass involved calculating the errors at each datapoint and tweaking the slope-intercept parameters accordingly
Learning Rate: Determines how quickly or slowly a model learns. In this case, the magnitude of the change made to the slope-intercept parameters at each iteration.
Unlike parameters, hyperparameters are not learned from the data. They are set prior to the training process as determined for better model performance.
2.9 Loss Function: Measuring Model Accuracy
A loss function evaluates how well your model predicts the target variable by comparing model predicted values to the actual values. From this comparison, the loss function calculates a score that gives feedback to the model on the appropriateness of its current set of parameters. In linear regression, a simple example would be the sum of the errors, but a more common metric is Mean Squared Error (MSE):
Understanding MSE:

where:
( y_i ) is the actual value.
( y-hat_i ) is the predicted value.
( n ) is the number of data points.
Minimizing the MSE is a key goal during the training process.
2.10 Gradient Descent: Finding the Optimal Parameters
The Analogy of the Foggy Mountain
Imagine you are descending a mountain shrouded in thick fog. Each step is uncertain—you can't tell if you're moving towards the valley, back up the peak, into a deceptive dip, or up a misleading rise. Your only clue is the ground's incline/decline underfoot. Instinctively, you choose to move in the declining direction. But there's a catch: small steps might trap you in a shallow depression, both directions inclining upwards, while large strides could free you but also entail risks.
This scenario mirrors a challenge in machine learning: tuning parameters. Like a hiker in the fog, we can't see the optimal parameter values or their effects until we take steps towards them. Here, the goal isn't descending a hill but minimizing a cost function. Instead of literal steps, we decide how much and in which direction to adjust parameters to reduce the cost. The dilemma is similar: small adjustments risk getting stuck in cost function's local minima, while large changes are riskier. The guiding factor, like the ground's slope for the hiker, is the cost function's gradient or slope—indicating whether a particular adjustment will increase or decrease the cost.
Gradient Descent is one such optimization algorithm used to minimize the loss function (like MSE) by iteratively deciding how the parameters of a model should be adjusted: in which direction and by how much.
How Gradient Descent Works:
Start with random values for the model's parameters.
Calculate the gradient/slope of the loss function concerning each parameter.
Update the parameters in the direction that reduces the loss function.
Repeat the process until the loss function is minimized or until a certain number of iterations.
Visualization of Gradient Descent
A graphical representation of how gradient descent optimizes the model's parameters. Here, the single vertical axis is the magnitude of the loss function, the two horizontal axes are parameters that are being adjusted (perhaps slope and intercept), finally the balls are the "travelers" or models adjusting and exploring parameter values as they learn.
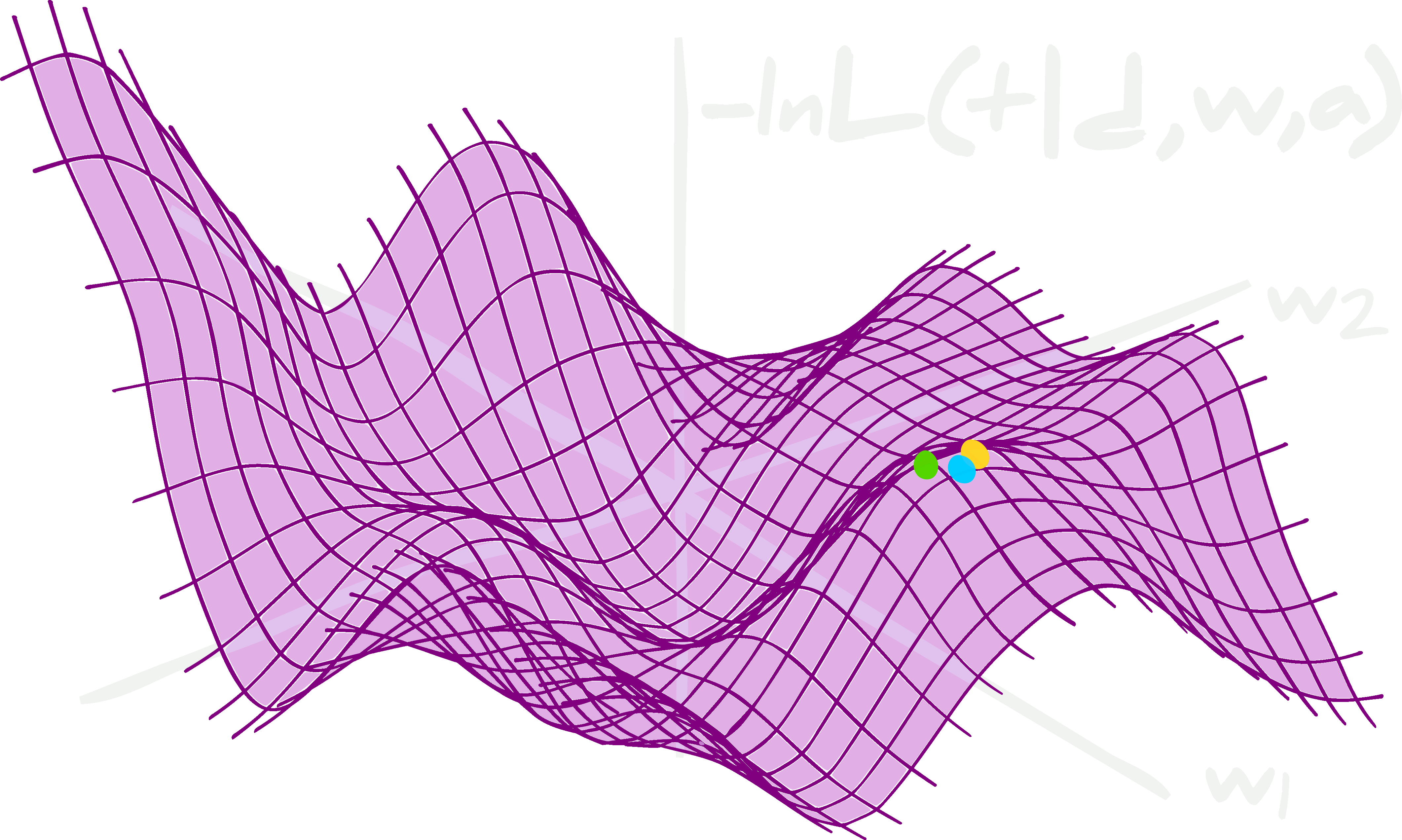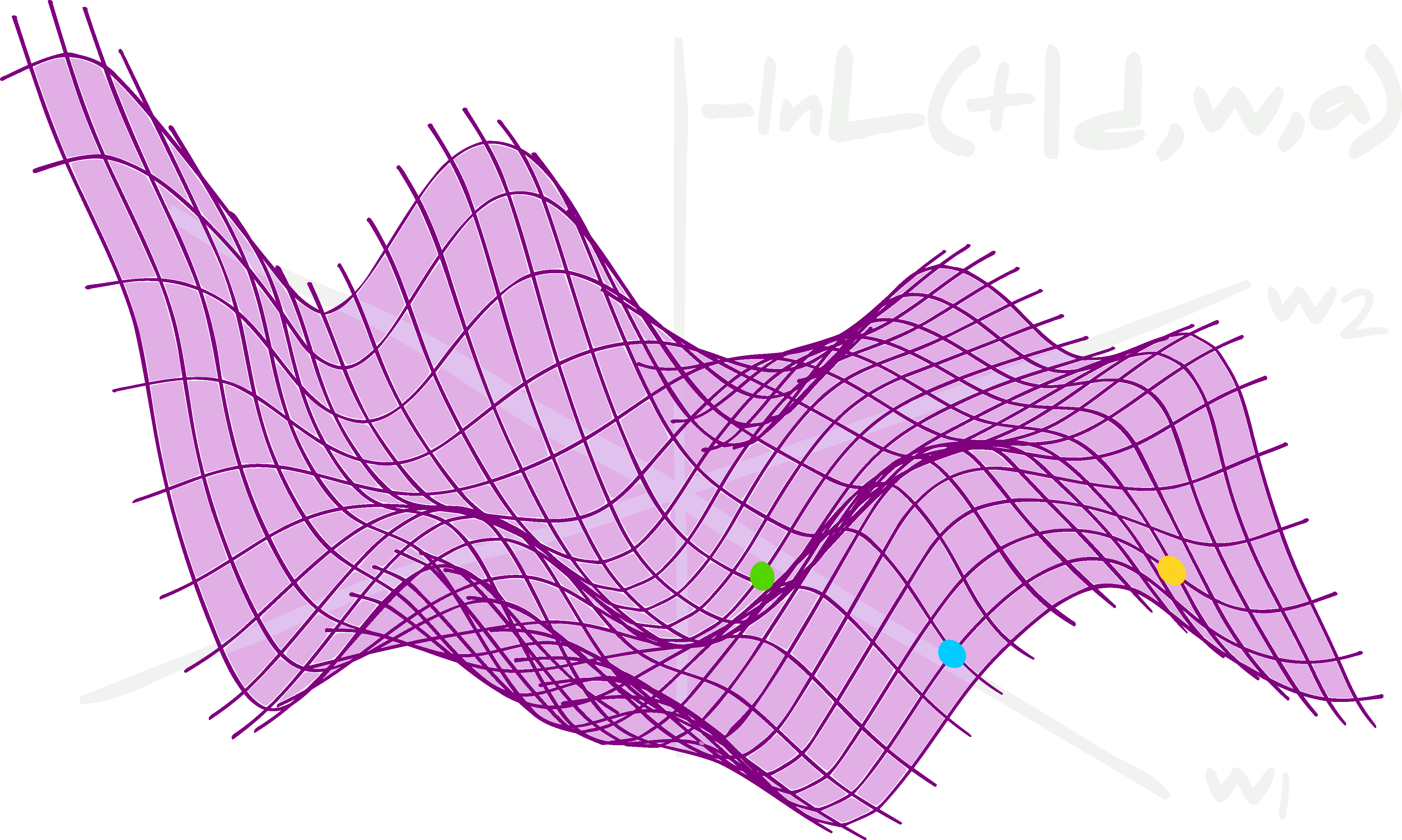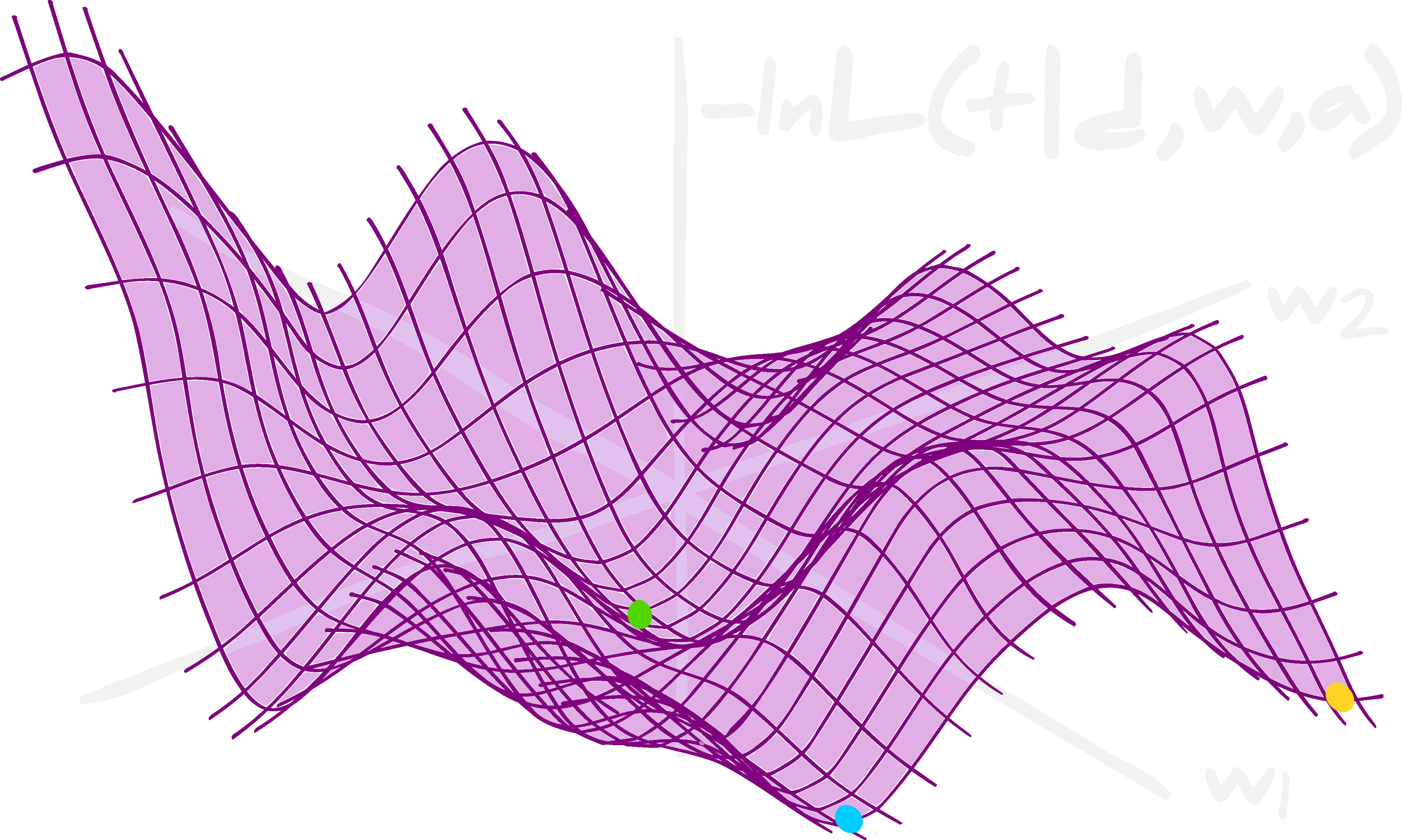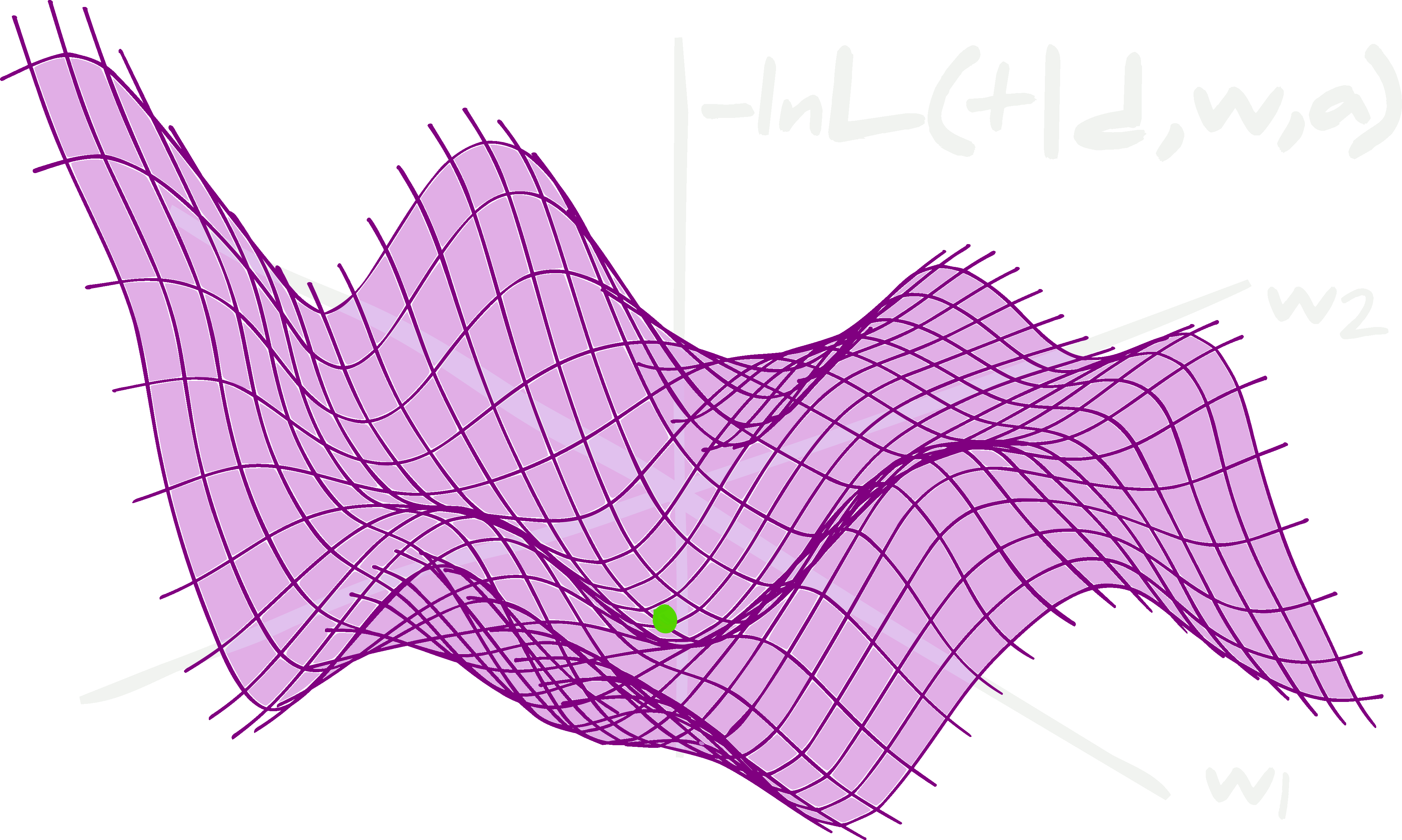
Conclusion
By applying linear regression, we've illustrated core ML concepts like parameters, hyperparameters, loss functions, and gradient descent. Understanding these concepts in the context of a simple model paves the way for grasping more complex algorithms in machine learning.